
Executive Summary
Kein einzelner Ansatz ist ausreichend. Die effektivsten Security Operations Center betreiben eine geschichtete Detection-Architektur, die Threat Intelligence, Business-Risikokontexte, Compliance-Anforderungen und kontinuierliche Qualitätsvalidierung kombiniert.
Kernerkenntnis: Die Organisationen mit den effektivsten Monitoring-Programmen sind nicht jene mit den größten Regel-Bibliotheken. Es sind jene, die bewusste, dokumentierte und kontinuierlich überprüfte Entscheidungen darüber treffen, was sie überwachen – und warum.
Die Detection-Engineering-Herausforderung
Die Frage „Was sollten wir überwachen?“ klingt simpel – ist es aber nicht. In der Praxis liegt sie im Schnittpunkt von Threat Intelligence, Business-Risikomanagement, Compliance-Pflichten und operativer Kapazität. Wer zu breit antwortet, ertränkt Analysten in Alerts ohne Signal. Wer zu eng antwortet, lässt echte Angriffe unentdeckt.
Diese Herausforderung verschärft sich in der Multi-Kunden-Realität moderner Managed Detection and Response-Anbieter: Ein einziger SOC muss gleichzeitig Kunden mit unterschiedlichen Industrien, Risikoappetiten, Technologie-Stacks, regulatorischen Umgebungen und Security-Reifegraden bedienen.
Fünf Bewertungsdimensionen
Jeder Ansatz wird entlang von fünf Dimensionen bewertet:
- Analyst-Erfahrung: Day-to-day Usability, kognitive Last, Regelqualität und Investigation-Erfahrung
- Organisationskosten: Tooling, Lizenzierung, Headcount, Skalierbarkeit und ROI-Timeline
- SOC-Management: Kunden-Reporting, Governance, Service Delivery und Team-Management
- Alert-Priorität: Wie der Ansatz Urgenz, Triage und Alert-Analyse beeinflusst
- Use-Case-Schweregrad: Wie genau der Ansatz Critical vs. Low Severity kalibriert
Ansatz 1: Threat-Driven – Der Angreifer als Ausgangspunkt
Threat-driven Ansätze starten beim Adversary und arbeiten sich rückwärts zur Detection-Logik vor. Statt zu fragen „Was produziert unsere Infrastruktur?“, fragen sie: „Was tun Angreifer tatsächlich – und welche Spuren hinterlassen sie?“ Diese Philosophie erzeugt die operativ relevantesten Use Cases – erfordert aber erhebliche Expertise und Investition.
MITRE ATT&CK Mapping
Das MITRE ATT&CK-Framework ist heute der Standard-Referenzrahmen für Adversary Techniques. SOCs nutzen es zur Coverage-Visualisierung, Gap-Analyse und als Zugang zu einer umfangreichen Bibliothek community-geschriebener Sigma-Regeln. Seine größte Stärke: ein gemeinsames Vokabular, das präzise Kommunikation zwischen Analysten, Kunden und Management ermöglicht.
Threat Intelligence-geführte Detection
Dieser Ansatz filtert die ATT&CK-Landschaft durch sektorspezifische Threat Intelligence – aus kommerziellen Feeds, ISACs oder interner Recherche – um zu identifizieren, welche Bedrohungsakteure die Industrie des Kunden aktiv angreifen. Das erzeugt Use Cases mit klarem Narrativ: „Wir überwachen auf die spezifischen Akteure, die Ihren Sektor ins Visier nehmen.“
Threat Modeling (STRIDE / PASTA)
Threat Modeling kartiert potenzielle Angriffspfade durch die spezifische Architektur des Kunden. Das Ergebnis ist ein kundenzentriertes Set von Überwachungsanforderungen auf Basis echter Angriffspfade. Severity-Zuweisungen sind hochgenau, da sie direkt aus dem Business Impact jedes modellierten Angriffspfads abgeleitet werden.
Red Team / Purple Team Output
Adversary-Simulation-Übungen liefern den hochwertigsten Use-Case-Input: Regeln aus echtem Angriffsverhalten im realen Environment. Purple-Team-Exercises schließen nachgewiesene Detection-Gaps direkt. Alert-Priorität und Severity sind für Kunden glaubwürdig und vertretbar.
Vorteile
- Höchste Detection-Relevanz – Use Cases an echtes Adversary-Verhalten gebunden
- ATT&CK liefert gemeinsames Vokabular und Community-Regel-Wiederverwendung
- Starkes Kunden-Narrativ: Monitoring spezifischer bekannter Bedrohungen
- Alert-Urgenz-Kontext aus Attribution beschleunigt Triage
- Kill-Chain-Awareness ermöglicht genaue Severity-Kalibrierung
Nachteile
- Hohe Expertise erforderlich; nicht skalierbar ohne skilled Analysten
- CTI-Feeds sind teuer; Intelligence-Lag erzeugt Detection-Lücken
- Threat Modeling ist per-Customer und kostspielig zu pflegen
- Red/Purple-Team-Input ist selten (typisch jährlich)
- Erzeugt Blind Spots für generische oder opportunistische Threats
Ansatz 2: Risk & Asset-Driven – Das Schutzobjekt zuerst
Risk- und Asset-getriebene Ansätze starten mit der Frage „Was wollen wir schützen – und welchen Schaden würde ein Versagen verursachen?“ Diese Philosophie stellt sicher, dass Monitoring-Investitionen proportional zum gefährdeten Business-Wert sind, und erzeugt Severity-Ratings direkt aus Business Impact – die glaubwürdigste Kalibrierungsgrundlage überhaupt.
Crown Jewel Analysis
Crown Jewel Analysis identifiziert Assets – Daten, Systeme oder Prozesse –, deren Kompromittierung den größten Business-Schaden verursachen würde. Monitoring Use Cases werden mit höchster Konzentration um diese Assets herum designt. Alerts, die definierte Crown Jewels berühren, werden automatisch in der Priorität erhöht.
Business Impact Analysis (BIA)
BIA quantifiziert den finanziellen, operativen und reputationsbezogenen Impact von Security-Ereignissen. Alert-Entscheidungen werden direkt: Ein Alert auf einem System mit 1-Stunden-RTO rechtfertigt per Definition sofortige Eskalation. Da BIA oft bereits für Disaster-Recovery-Zwecke existiert, können SOC-Teams bestehende Analysen nutzen.
Attack Surface Mapping
Attack Surface Mapping inventarisiert alle bekannten Einstiegspunkte – internet-facing Systeme, Identity Provider, Supply-Chain-Verbindungen und Shadow IT. Internet-facing Assets tragen per Default höhere Severity, da externe Exponierung das Zeitfenster zwischen Angriff und Kompromittierung verengt.
Vorteile
- Severity aus echtem Business Impact – glaubwürdigste Kalibrierungsbasis
- Vermeidet Over-Monitoring von Low-Value-Assets; fokussiert Budget auf Wesentliches
- Crown Jewel Alerts können automatisch elevated werden
- BIA existiert oft bereits (Disaster Recovery) – reduziert Analyse-Overhead
- Einfach gegenüber Executives und Board Stakeholders zu rechtfertigen
Nachteile
- Angreifer pivoten durch Low-Value-Assets zu Crown Jewels – Lateral-Movement-Lücken
- Kunden können kritische Assets oft nicht einigen oder dokumentieren
- Asset-Kritikalität ändert sich mit dem Business; erfordert Re-Assessment
- BIA-Sprache übersetzt sich nicht intuitiv in Detection-Logik
- Severity basierend auf Impact allein ignoriert Angriffswahrscheinlichkeit
Ansatz 3: Compliance & Baseline-Driven – Der regulatorische Mindeststandard
Compliance- und Baseline-Ansätze definieren Monitoring-Anforderungen aus extern vorgegebenen Standards. Sie stellen den schnellsten Weg zu einer dokumentierten Monitoring-Baseline dar. Ihre Schwäche: Regulatorische Mandaten sind für Compliance-Auditoren designed, nicht für Angreifer – die beiden haben sehr unterschiedliche Ziele.
Regulatorische Anforderungen (NIS2 / PCI-DSS / ISO 27001 / DORA)
Regulatorische Frameworks mandatieren spezifische Monitoring-Pflichten – Zugriffe auf privilegierte Accounts, Datentransfer-Logging, Authentifizierungs-Events –, die eine nicht verhandelbare Mindestbasis liefern. Alert-Urgenz kann an regulatorische Verletzungsfristen gebunden werden, z.B. die 72-Stunden-GDPR-Meldepflicht. Compliance-Coverage ist jedoch nicht darauf ausgelegt, reale Angriffspfade abzudecken.
Sigma / Community Use Case Libraries
Open-Source-Rule-Libraries – insbesondere das Sigma-Format-Ökosystem – stellen Tausende community-gepflegter Detection-Regeln bereit. Sie reduzieren die Time-to-Detection für neue Kunden dramatisch. Community-Severity-Ratings sind allerdings stets auf das spezifische Kunden-Environment zu rekalibrieren.
Log Source Coverage Matrix
Eine Coverage Matrix stellt sicher, dass jede Log-Quelle, die den SIEM speist, mindestens ein Minimum an zugehörigen Detection-Regeln hat und verhindert so „dunkle“ Quellen, bei denen Daten gesammelt, aber nie überwacht werden.
Vorteile
- Jede Regel hat eine klare, auditierbare externe Rechtfertigung
- Schnellster Weg zu einer dokumentierten Baseline – niedrigster Implementierungsaufwand
- Sigma Libraries: kostenlos, portabel und community-gepflegt
- Coverage Matrix verhindert ungovernte Log-Quellen
- Sektorweit über alle Kunden im gleichen regulierten Umfeld wiederverwendbar
Nachteile
- Compliance ≠ Security: erzeugt gefährliche False Confidence
- Community-Severity-Ratings müssen pro Environment rekalibriert werden
- Hohe False-Positive-Rate ohne umgebungsspezifisches Tuning
- Darf nicht primäre Strategie sein – behandelt Audit-Scope als Threat-Model
- Verschiedene Standards pro Kunde fragmentieren Regelwerk bei Skalierung
Ansatz 4: Data & Analytics-Driven – Der SOC als Messsystem
Data- und Analytics-Ansätze behandeln den SOC primär als Messsystem und sekundär als Detection-System. Statt zu fragen „Was soll auslösen?“, fragen sie kontinuierlich: „Was löst tatsächlich aus, wie ist die Signal-Qualität – und wie können wir kontinuierlich besser werden?“
Detection-as-Code / Rule Lifecycle Management
Detection-Regeln wie Software zu behandeln – mit Versionskontrolle, automatisiertem Testing, CI/CD-Deployment-Pipelines und Performance-Metriken – erzwingt eine Qualitätsdisziplin, die kein anderer Ansatz replizieren kann. Schwache Regeln werden deaktiviert statt Rauschen zu produzieren.
UEBA / Behavioural Baselining
User and Entity Behaviour Analytics baut statistische Baselines für User, Hosts und Service Accounts auf und alertet bei statistisch signifikanten Abweichungen. Besonders effektiv gegen Insider Threats und langsame Credential-Abuse-Kampagnen. Dynamische Entity Risk Scores liefern einen kontextbewussten Alert-Priorisierungs-Layer.
Alert Fatigue-Driven Prioritisation
Eine Regel mit 2% TP-Rate, die 500 Mal täglich feuert, ist keine Detection – sie ist betriebliche Schuld, die als Detection getarnt ist. Regelmäßige Fatigue-Analysen legen dies offen und schaffen die nötige Kapazität für hochwertige Detektionen.
Vorteile
- Einziger Ansatz, der Detection-Qualität kontinuierlich mit echten Daten validiert
- UEBA erkennt novel Angriffe, die statische Regeln vollständig verpassen
- Alert-Fatigue-Reviews verbessern direkt Analysten-Kapazität und Motivation
- Detection-as-Code skaliert Quality-Governance über große Kunden-Portfolios
- Severity-Fehlkalibrierung wird automatisch erkannt und über Zeit korrigiert
Nachteile
- Höchste Maturity-Anforderungen aller Ansätze
- UEBA Black-Box-Alerts schwer zu triagen und gegenüber Kunden zu erklären
- Detection-as-Code erfordert Engineering-Kultur-Shift im SOC
- Alert-Fatigue-Analyse ist reaktiv – keine Orientierung für neue Use Cases
- Volume-basierte Suppression kann seltene Critical-Severity-Alerts verbergen
Vergleich: Alle Ansätze im Überblick
Die folgende Tabelle vergleicht alle Ansätze entlang der fünf Bewertungsdimensionen:
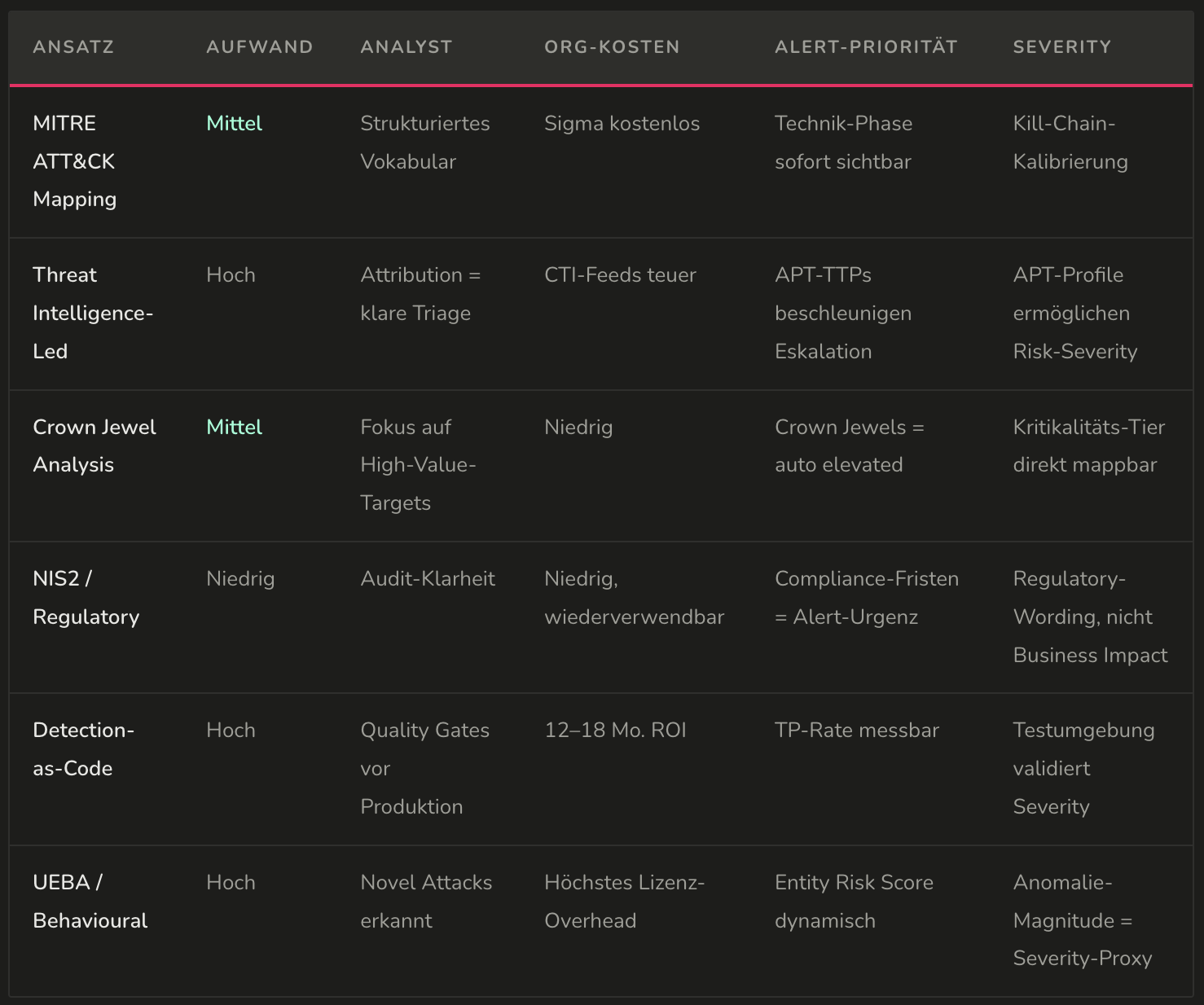
Die beste Strategie: Ein geschichteter Ansatz
Kein einzelner Ansatz ist für sich ausreichend. Jede der vier Kategorien kompensiert Schwächen der anderen: Threat-Driven Ansätze liefern Relevanz, Risk-Driven Ansätze liefern Business-Alignment, Compliance-Driven Ansätze liefern Auditierbarkeit, Data-Driven Ansätze liefern kontinuierliche Qualitätsvalidierung.
Kritischer Hinweis: ATT&CK ohne CTI erzeugt breite, aber unfokussierte Coverage. CTI ohne ATT&CK fehlt der strukturelle Rahmen. Beide müssen von Beginn an gemeinsam eingesetzt werden.
Die empfohlene Vier-Schichten-Detection-Architektur
Schicht 1: Threat-Informed Foundation
MITRE ATT&CK + Threat Intelligence-Led + Log Source Coverage Matrix
Struktur und Relevanz simultan. ATT&CK liefert das Vokabular; sektorspezifische Threat Intelligence filtert auf das reale Threat-Profil des Kunden. Niedrige Kosten, schneller Deployment.
Schicht 2: Customer Context
Onboarding Workshop + Crown Jewel Analysis
Generische Regeln werden ohne kundenbezogenen Kontext gefährlich. Höchster marginaler Return mit niedrigstem Tooling-Aufwand. Wird in MSSP-Programmen am konsequentesten unterbewertet.
Schicht 3: Governance
SLA Tiering + Continuous Review Cycles (quartalsweise)
Alert-Priorität wird operativ konkret und vertraglich durchsetzbar. Verhindert Rule Decay.
Schicht 4: Advanced (für mature Kunden)
UEBA oder Detection-as-Code
Höchstes Ceiling, aber nur sinnvoll wenn das Fundament solide ist. Selektiv für Enterprise-Kunden.
Zwei kritisch unterbewertete Ansätze
Der Onboarding Workshop wird konsistent unterschätzt. Bei nahezu null Tooling-Kosten erfasst er kundenzentrierten Kontext – Legacy-Systeme, vergangene Incidents, undokumentierte Business-Risiken –, den kein automatisiertes Tool liefern kann.
Alert Fatigue-Driven Prioritisation liefert das ehrlichste Signal darüber, ob das Monitoring-Programm funktioniert. Eine Regel mit 2% TP-Rate, die 500 Mal täglich feuert, ist keine Detection – sie ist betriebliche Schuld.
Den einen Ansatz, der als primäre Strategie vermieden werden sollte
Regulatorische Compliance als primärer Treiber für Use-Case-Definition ist der häufigste Fehler in Managed Security Services. Sie erzeugt die Illusion von Coverage und produziert Regeln für Auditoren – nicht für Angreifer. Compliance sollte als parallele Randbedingung laufen, nie als Motor.
Fazit
Use Cases zu definieren und zu priorisieren ist eine der folgenreichsten Entscheidungen, die ein SOC trifft – und eine der am wenigsten systematisch governance-geführten. Die vier analysierten Ansätze sind keine gegenseitig ausschließenden Alternativen – sie sind komplementäre Schichten.
ATT&CK und Community Libraries liefern die Baseline. Customer Workshops und Crown Jewel Analysis liefern Business-Alignment. Sektorspezifische CTI liefert Relevanz. Continuous Review und Alert Fatigue Analysis liefern operationale Disziplin. Detection-as-Code und UEBA liefern Skalierbarkeit und Novel-Threat-Coverage für reife Programme.
Die Organisationen mit den effektivsten Monitoring-Programmen sind nicht jene mit den größten Regel-Bibliotheken. Sie sind die, die bewusste, dokumentierte und kontinuierlich überprüfte Entscheidungen darüber treffen, was sie überwachen – und warum.
apt-one GmbH ist ein spezialisierter Managed Detection and Response-Anbieter mit Fokus auf den Aufbau hochfidelity, kundenzentrierter Security Monitoring Programme für Organisationen in ganz Europa. Wir arbeiten eng mit unseren Kunden zusammen – von der initialen Bedrohungsanalyse bis zum laufenden Monitoring – und verstehen Security nicht als Produkt, sondern als kontinuierlichen Prozess.
Bereit, Ihre Sicherheitslage auf das nächste Level zu heben? Sprechen Sie direkt mit unseren Security-Experten – unverbindlich und auf Augenhöhe.
Ähnliche Beiträge

Incident Response – Eradication
Eradication is the turning point of incident response. It’s where you move beyond containment to fully eliminate…

Open Source SIEM Solutions
Open-source SIEM solutions offer cost-effective, customizable, and flexible network security monitoring. However,…

Awareness Kampagne
Cybersicherheit beginnt beim Menschen. Erfahren Sie, warum eine Awareness-Kampagne entscheidend ist, um Wissenslücken…